日文乱码转换 Java 的具体实现方法
在 Java 编程的世界中,处理日文乱码转换是一个常见但又颇具挑战性的任务。正确地处理日文乱码转换对于确保应用程序能够准确地处理和显示日文文本至关重要。
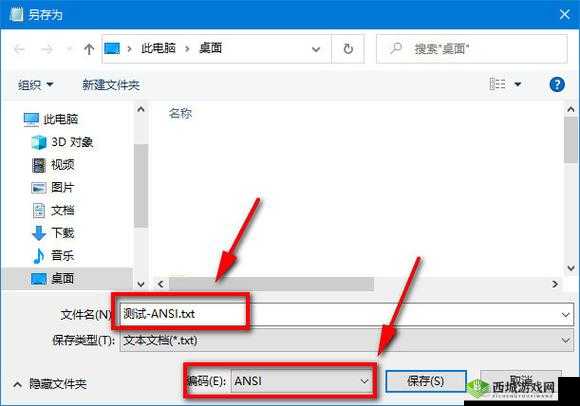
我们需要了解乱码产生的原因。这通常是由于字符编码的不一致导致的。在 Java 中,常见的字符编码有 UTF-8、UTF-16、Shift_JIS 等。当输入的日文文本使用的编码与程序处理时所期望的编码不乱码就会出现。
为了实现日文乱码的转换,我们可以使用 Java 的`InputStreamReader`和`OutputStreamWriter`类。通过指定正确的编码,我们可以读取和写入日文文本。
例如,如果我们从一个文件中读取日文文本,并且已知该文件使用的是 Shift_JIS 编码,我们可以这样做:
```java
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("your_file.txt"), "Shift_JIS"))) {
String line;
while ((line = reader.readLine())!= null) {
// 在这里对读取到的每行日文文本进行处理
}
} catch (IOException e) {
e.printStackTrace();
```
同样,如果我们要将处理后的日文文本写入到另一个文件中,并且希望使用 UTF-8 编码,可以这样实现:
```java
try (BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("output_file.txt"), "UTF-8"))) {
// 写入处理后的日文文本
writer.write("您的日文文本");
} catch (IOException e) {
e.printStackTrace();
```
在处理网络请求或响应中的日文乱码时,我们也需要注意设置正确的编码。例如,在发送 HTTP 请求时,可以通过设置请求头中的`Content-Type`来指定编码。
在实际的开发中,为了确保程序的健壮性,我们还应该添加适当的错误处理代码。当遇到无法识别的编码或转换错误时,能够给出清晰的错误提示,以便及时进行排查和修复。
对于一些复杂的日文文本处理场景,可能需要使用更专业的库和工具,比如 `ICU4J` 库,它提供了更强大和全面的字符编码处理功能。
实现日文乱码转换在 Java 中需要我们对字符编码有清晰的理解,并且熟练运用相关的类和方法。通过正确地设置编码和处理输入输出流,我们能够有效地解决日文乱码的问题,确保我们的应用程序能够准确地处理和展示日文文本,为用户提供良好的体验。
在不断的实践和探索中,我们会积累更多的经验,能够更加灵活和高效地应对各种日文乱码转换的需求,让我们的 Java 程序在处理多语言文本,特别是日文文本时,表现得更加出色。